In this post, we'll explain how Raft handles read only requests.
To those who are unfamiliar, Raft is an algorithm that replicates a shared state to a group of servers using leader election. Raft maintains a change log that is consistent among all replicas. The log is append-only. Each change to the shared state is turned into a new entry in the log. New log entries must be agreed upon by a quorum of replicas to be considered permanent ("committed"). Write requests are managed as log entries. The leader proposes one new log entry for each write, then gathers enough support so that it could be committed. The application applies committed entries in the log sequentially, and answers the corresponding write requests as it goes. We could process read requests the same way. A read request is just a no-op write request. Problem solved.
But this is not good enough. In real life, the number of read requests usually dominates write requests. Converting all read requests into expensive writes is less than ideal. The Raft paper mentioned we could make the Raft log much shorter by skipping the new commit for read requests.
Pitfalls
Let's take a step back. Why do we need the commit for a read request? As the leader, can't we just serve read requests with the current log in memory? The answer is no. We don't always know if we are still the leader when answering new requests. We are not sure if the log we have is up-to-date. It could be the case that we were the leader, but have lost contact with other replicas. If another replica has become the leader and committed a new log entry, we might not even know. If the new leader has revealed the new committed entry to clients, clients may observe inconsistency in the shared data. The Raft paper mentioned we must not return "stale" data. We'll see that the definition of "stale" is a bit surprising.
This might lead to a "lease" based solution. As the leader we maintain a time-bound lease from all of the followers. As long as the lease is alive, we are still the leader. This solution requires a bounded clock skew between replicas. Can we do better, without relying on the clock?
Am I the leader? Just ask around
There is another way to confirm that we are still the leader. We can just ask around. Send a heartbeat to each follower. If they reply OK, they must think we are still the leader. Once we have a quorum (similar to writes), we can be assured that we are the leader. It sounds like this could work, just like another way of creating "pretend" commits that do not exist in the log. But it also sounds like there can be a lot of timing issues. Some confirmation comes before others, and there could be writes in between. Which view should we return as the "consistent" view?
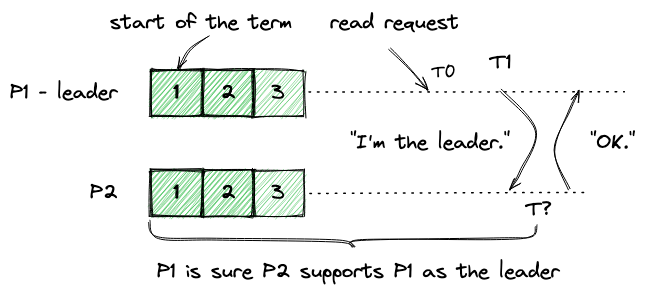
Let's take a deeper look. Imagine I'm the leader and received a readonly request at time T0. To confirm my leadership, I sent a heartbeat with my term to a follower at time T1. The follower replied OK. The follower only replied OK when it did not know any new terms after my term. Thus the follower believes I was still the leader when it sent the reply back. We have no idea when exact that is (T?), but we are sure it is after T1( T? > T1). A term in Raft is always continuous in time. If the follower supports our leadership at T?, it also does at T1. As the leader, we can safely conclude that at least until time T1, the follower believes I'm still the leader.
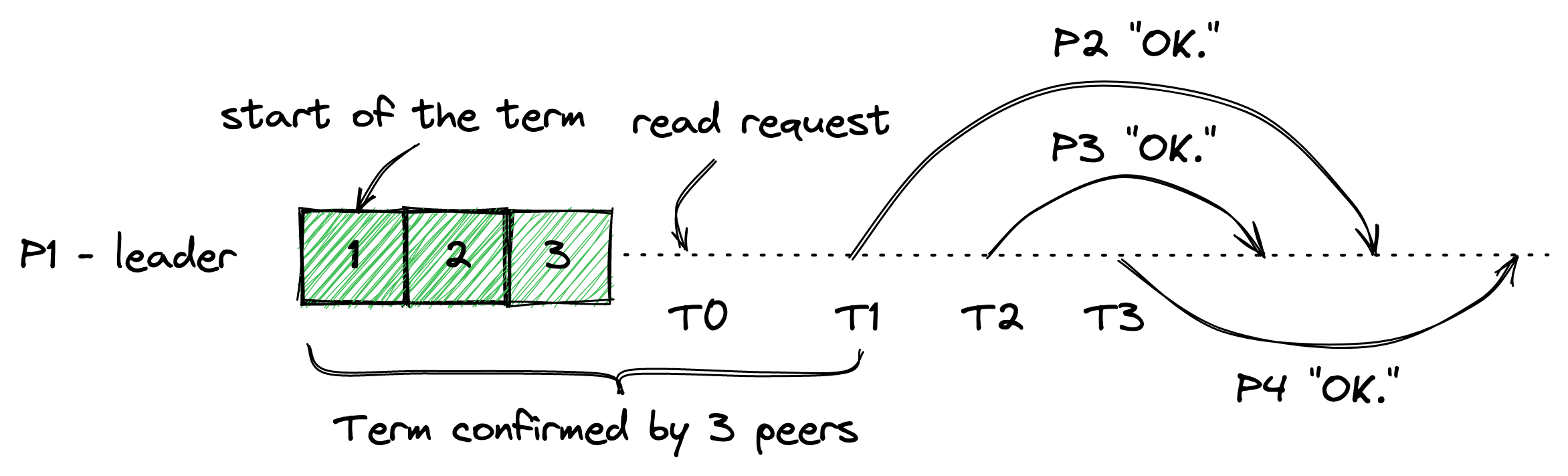
Now if 3 of my peers think I'm the leader on T1, T2, and T3, we know they all believed I'm the leader up to the time of min(T1, T2, T3). One caveat is that we were the leader at T1, but we might not still be the leader at T3, since the confirmation from the first peer has expired.
The consistent view
Since we are the leader at time T1, our view at time T1 must be consistent. We can respond to the readonly request with our view at T1, which is uniquely identified by the leader commit index at time T1. Problem solved!
By the linearizability rule, we can actually return any state after time T0, as long as we are still the leader of the same term as T0. After all, the client has no insight on when T1 is, just like we don't know when T? is. We can pretend several commits have happened after T0 but before T1. If that is the case, we could have included the commits in the response to the client. Things are more complicated when we are on a different term. We will discuss this scenario more in the next post.
Guaranteed no new commit
We can also prove that no new commit could have been created at time T1, if a quorum confirmed our leadership after T1. It is a bit dry but here is how it goes.
- Hypothesis 1: I am the leader, and more than half of the cluster confirmed my leadership at
T1. - Hypothesis 2: At physical time
T1, a new log entry has been committed without me noticing.
Proof by contradiction
- Me as the leader of the current term, did not commit anything at time
T1. The commit must be created by a new leader, and must be for a new term after my term. - To commit the new entry, at least half of the cluster must have accepted the commit at time
T1. - Thus, more than half of the cluster must have learnt about a new term, when they accepted the new commit.
- Thus, more than half of the cluster will not answer a heartbeat of my term at or after time
T1. This contradicts Hypothesis 1.
In fact, this is how "no stale data" is defined: at T1, no new changes are made. This definition is a bit strange, in the sense that by the time we get the quorum (T?), the commit at T1 is already stale. Yet we could safely serve data at T1 without breaking any linearizability rule.
Does the leader always have a consistent view?
At first glance, it seems obvious. How can the leader not have a consistent view? Actually, the leader knows everything except in one edge case: at the start of the new term.
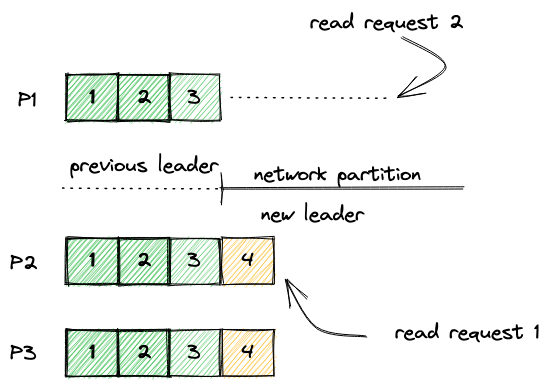
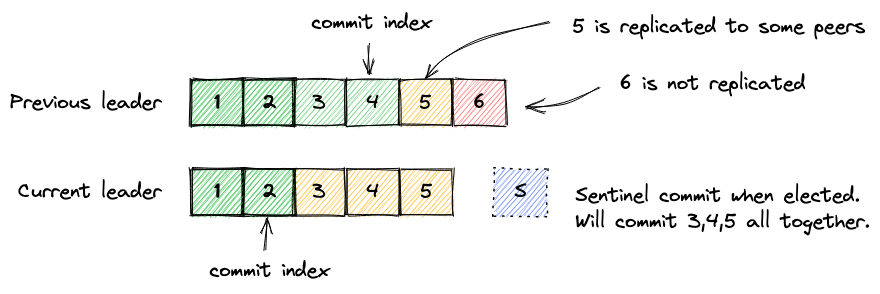
As a newly-elected leader, we have the full log, but we don't know the exact commit index. Consider the diagram below. When the new term begins, the previous leader did not send the most up-to-date commit index to us. Without a concrete commit index, we don't know what the previous leader has considered "committed" (Is it 2, 3, 4, or 5?). Then we can't answer read queries without knowing which entry has been exposed, or whether the entry is actually committed or not. In fact, commit #5 is not guaranteed to survive the term change. The best we can do is to commit a new entry immediately after the election. The commit index will turn concrete once S is committed. All read requests have to be held until the first entry of the term is committed. More precisely, any T1 mentioned above has to be on or after the first entry is committed. This workaround is mentioned in the Raft paper.
Summary
To serve a read only request in Raft, as proposed by the original paper, we should
- Commit an empty sentinel log entry at the beginning of each term. Save the index of the sentinel commit for the next step.
- When a read request arrives, check if we are the leader. If so, store the current commit index together with the read request. This index marks the view we are going to use. If the index is smaller than the sentinel index, use the sentinel index instead.
- Send heartbeats to followers and confirm our authority by acquiring a quorum.
- Wait until the empty sentinel entry of our term is committed.
- Reply to the read request with data seen at the commit index saved in step 2. The application is free to reply with any state on or after the commit index.
In the next post, we'll look at it from a practical angle, see how it should be implemented, and how we can improve.